
目前MySQL支持的索引主要有哈希索引、B+树索引、全文索引(fulltext index)、空间索引。平时用到最多的当属B+树索引。今天我们就来看看InnoDB和MyISAM存储引擎的索引实现方式。
InnoDB索引介绍
所谓的B+树是从平衡二叉树(AVL)演化来的,它是一个典型的多路平衡搜索树。
MySQL中InnoDB的B+树索引分为clustered index和non-clustered index,也就是聚集索引和非聚集索引。聚集索引是按表的主键构造一颗B+树,其叶子节点存放着整条的记录数据,非聚集索引的叶子节点只保存了主键值和对应的偏移量。下图就是一颗典型的B+树聚集索引的简化结构:
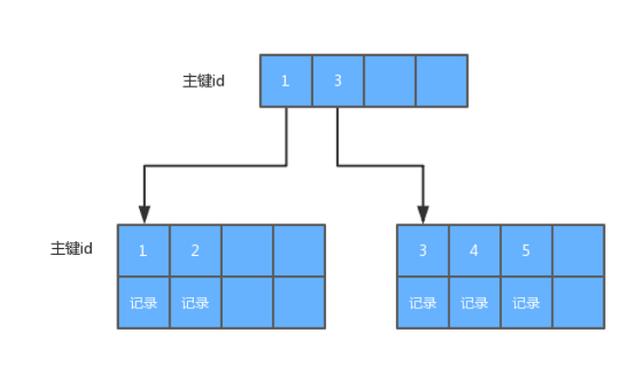
我们再来看看非聚集索引的:
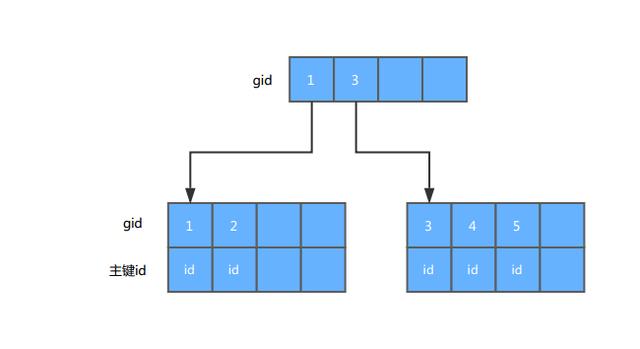
区别十分明显,叶子结点上存放的数据不同,回想一下,之前说到的覆盖索引为什么查找速度会很快(不清楚的先往下看,然后再去翻翻之前文章了解)。
覆盖索引之所以快,是因为省去了二次查找,仅仅查找索引文件便可获取到所有查询所需的字段(语句查找字段,条件字段,排序字段都在一个联合索引中),非聚集索引文件本身就小很多,查找起来非常快。如果查找的字段不全在非聚集索引中,那么存储引擎就只能拿到主键之后再用主键去聚集索引中获取数据了,在数据量大的情况下就会慢很多。
接下来,我们看看MyISAM的实现方式:
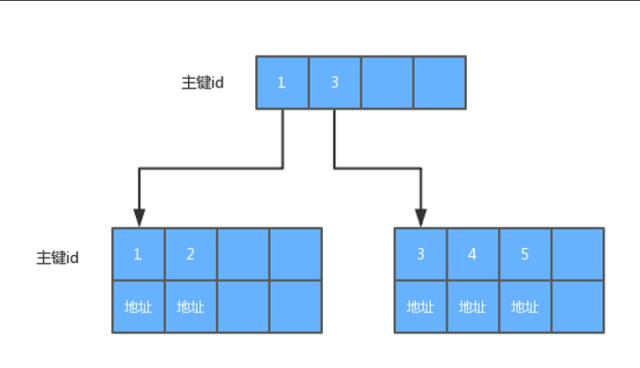
无论哪种索引,键值上对应的都是数据在磁盘上的物理地址,区别只是主键索引的值不能重复而已。
通常,B+树索引效率都很高,树的高度并不高,I/O次数较少。但是,它也不是没有缺点,数据量越大,每次更新数据树的变动(保持平衡)也越大,超过一定数量后性能便会直线下降,这也是为什么大表性能低的原因。